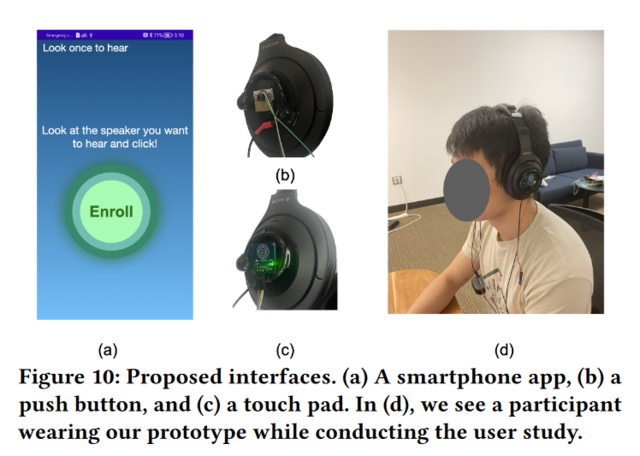
近日,华盛顿大学的研究团队研发出了一种利用人工智能实现实时主动降噪的方法。这种方法可以在保留耳机音频质量的同时,消除用户指定的背景噪音。
该研究团队由人工智能专家Shyam Gollakota带领,于5月16日在美国声学学会和加拿大声学协会召开的一次会议上展示了这一技术,并提供了一个工作原型。
研究团队使用基于智能手机的神经网络来识别、训练和过滤20种不同的环境声音类别,例如常见的警报声和闹钟声等。
Gollakota教授表示:“想象一下,在公园里欣赏鸟儿的叫声时,旁边有人在大声喧哗,你却无法让其停止说话。这种情况下,我们的系统可以帮你专注听鸟叫声,并且让其他噪音消失。”
根据展示的原型来看,耳机耳罩两侧配备有麦克风,并通过USB连接到一块香橙派电路板。电路板还通过音频插孔为耳机提供音频信号。
根据电路板的布局,很可能是OrangePi 5B型号,搭载了Rockchip RK3588S SoC(八核64位处理器,内置神经处理器,计算能力为6Tops),可进行实时过滤。
研究团队表示,经过人工智能训练后,在不到百分之一秒的时间内就可以完成实时主动降噪操作,而这样做并不会抑制耳机播放的实际声音。
文章引用:
Look Once to Hear: Target Speech Hearing with Noisy Examples




发表评论 取消回复